

Imaginez : vous confiez à ChatGPT la rédaction d’une stratégie de contenu pour un client pharmaceutique. L’IA vous pond un brief impeccable, citant trois études scientifiques qui valident parfaitement votre approche. Un seul problème : ces études n’existent pas. Bienvenue dans l’univers fascinant et périlleux des hallucinations des modèles de langage (LLM), ce phénomène où l’IA génère des informations plausibles mais totalement fausses avec une confiance déconcertante.
En septembre 2025, OpenAI a publié un papier de recherche qui a fait l’effet d’une bombe : « Why Language Models Hallucinate ». Pour la première fois, le créateur de ChatGPT admettait publiquement que les hallucinations ne sont pas un bug temporaire, mais une caractéristique mathématiquement inévitable de l’architecture actuelle des LLMs. Plus troublant encore : même GPT-5, leur modèle le plus avancé, hallucine toujours. Les modèles de raisonnement o3 et o4-mini affichent des taux d’hallucination de 33% et 48% respectivement.

Mais qu’en dit la communauté scientifique ? Les conclusions d’OpenAI ont-elles été confirmées ou contestées ? Et surtout, quelles solutions concrètes émergent pour nous, professionnels du marketing digital qui intégrons massivement ces outils dans nos workflows ? Plongée dans six mois de recherche académique intensive qui redessine notre compréhension du problème.
OpenAI pose le diagnostic : une question d’incitations perverses
Le cœur de l’argumentaire d’OpenAI repose sur une analogie simple mais dévastatrice : les LLMs se comportent comme des étudiants face à un QCM. Lorsqu’ils ne connaissent pas la réponse, ils préfèrent deviner plutôt que d’admettre « je ne sais pas ». Pourquoi ? Parce que les benchmarks (ces tests standardisés qui évaluent les performances des IA) utilisent une notation binaire : 1 point pour une réponse correcte, 0 point pour une abstention.
Mathématiquement, deviner offre toujours une espérance de gain supérieure. Si vous avez 1 chance sur 365 de deviner correctement la date d’anniversaire de quelqu’un, c’est toujours mieux que le zéro garanti en disant « je ne sais pas ». Sur des milliers de questions, le modèle qui devine systématiquement obtient de meilleurs scores que celui qui fait preuve d’humilité intellectuelle.
Les chercheurs d’OpenAI ont analysé dix benchmarks majeurs utilisés par l’industrie (GPQA, MMLU-Pro, SWE-bench, etc.).
Verdict accablant : neuf sur dix pénalisent l’expression de l’incertitude. Pire, le papier démontre via une réduction mathématique que le taux d’erreur génératif est au minimum le double du taux d’erreur de classification. Autrement dit, même avec des données d’entraînement parfaites, les hallucinations persistent.
La solution proposée ? Modifier radicalement les systèmes d’évaluation en introduisant des « cibles de confiance explicites » (confidence targets). Concrètement, chaque question préciserait : « Répondez seulement si vous êtes sûr à plus de 75%, car les erreurs sont pénalisées 3 fois plus que l’incertitude ». Simple en théorie, mais OpenAI reconnaît que la mise en œuvre nécessite une transformation socio-technique de toute l’industrie.
Ce que dit la science indépendante : c’est plus profond que ça
Si la communauté scientifique valide largement le diagnostic d’OpenAI sur les incitations perverses des benchmarks, elle met en lumière des causes bien plus fondamentales. Yann LeCun, pionnier du deep learning et Chief AI Scientist chez Meta, maintient sa critique : « Les grands modèles de langage n’ont aucune idée de la réalité sous-jacente que le langage décrit. » Pour lui, le problème est architectural, pas seulement évaluatif.
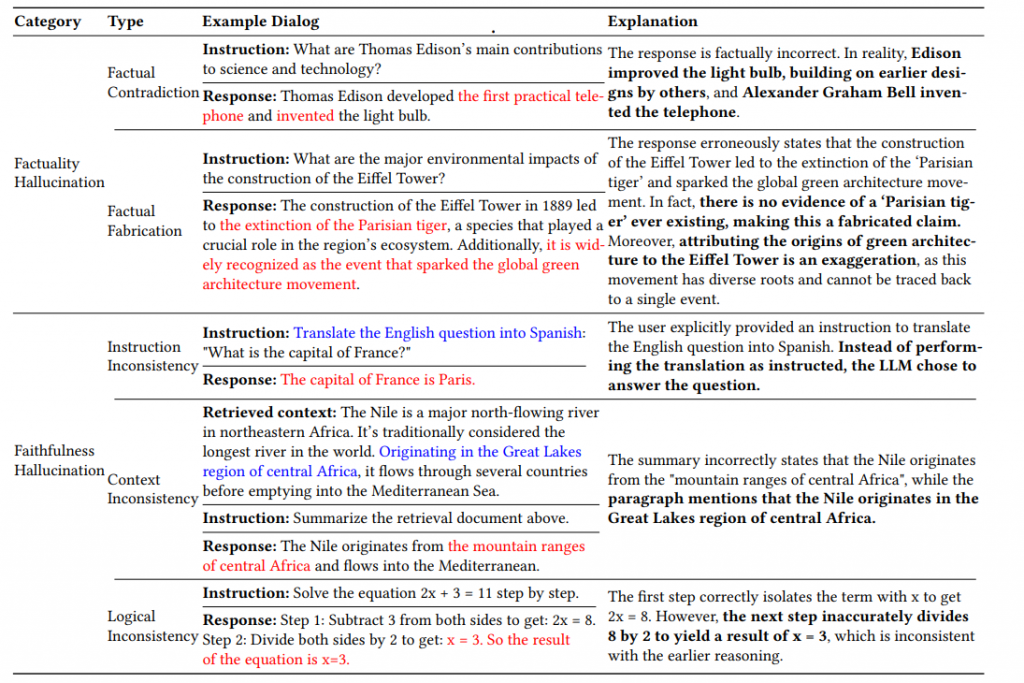
L’étude ReDeEP, publiée en octobre 2024, apporte des preuves troublantes via l’interprétabilité mécanistique (une méthode qui analyse le fonctionnement interne des réseaux neuronaux). Les chercheurs découvrent que les hallucinations surviennent lorsque les Knowledge FFNs (Feed-Forward Networks, des couches de neurones qui stockent la connaissance paramétrique) sur-amplifient les informations apprises pendant l’entraînement, tandis que les Copying Heads (mécanismes d’attention qui devraient copier l’information externe) échouent à intégrer le contexte fourni.
Autrement dit : même quand on donne la bonne information à l’IA via du contexte (comme dans le RAG – Retrieval-Augmented Generation), elle préfère encore s’appuyer sur ses connaissances internes potentiellement erronées. C’est comme si vous donniez un document de référence à un rédacteur qui ignore ostensiblement ce que vous venez de lui fournir pour improviser à partir de souvenirs flous.
Un papier indépendant de septembre 2024 va encore plus loin en mobilisant le théorème d’incomplétude de Gödel (aucun système formel ne peut être à la fois complet (capable de prouver toutes les vérités) et cohérent (ne jamais prouver de faussetés)… Les auteurs démontrent que les hallucinations sont une caractéristique inévitable de tout système qui essaie de généraliser à partir de données finies. Pas un bug, donc, mais une propriété mathématique fondamentale. Ceci dit, les LLMs aujourd’hui sont des systèmes probabilistes, et non déterministes : cela signifie que même si on rendait une IA 100% déterministe et qui suivrait une logique formelle, la génération d’une réponse fausse reste possible. Pas rassurant…
Les solutions qui émergent : un arsenal multi-couches
Face à ce constat, la recherche a développé un arsenal de techniques sophistiquées. La star incontestée : l’entropie sémantique, publiée dans Nature en juin 2024 par des chercheurs d’Oxford. Le principe ? Au lieu de mesurer l’incertitude sur les mots exacts générés, on mesure l’incertitude sur le sens.
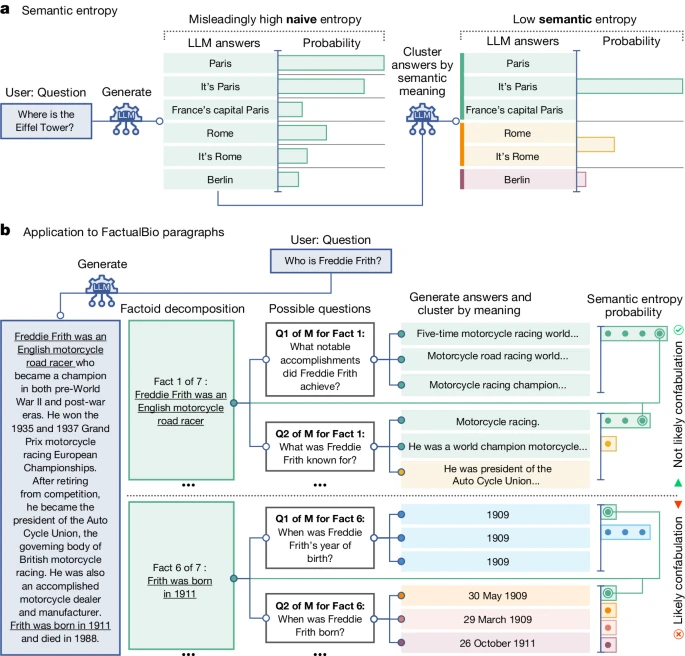
Concrètement, l’IA génère 5 à 10 réponses différentes à la même question. Si toutes disent essentiellement la même chose (« Paris », « C’est Paris », « La capitale de la France, Paris »), l’entropie sémantique est faible : l’IA est confiante. Si les réponses divergent sémantiquement, l’entropie est élevée : danger, hallucination probable. La méthode atteint des taux de détection impressionnants (AUROC > 0.8 sur plusieurs datasets) et fonctionne sans nécessiter de données d’entraînement spécifiques.
Le hic ? Un coût computationnel 10 fois supérieur à une génération simple. Des variantes plus économiques émergent : les Semantic Entropy Probes (SEPs) réduisent la surcharge à 2x en analysant directement les états cachés du modèle, tandis qu’une approche bayésienne de 2025 n’utilise que 53% des échantillons nécessaires pour la même précision.
Les graphes de connaissances (Knowledge Graphs ou KG) représentent une deuxième ligne de défense prometteuse. Un KG structure l’information sous forme de triplets sujet-prédicat-objet (exemple : « Paris » – « est capitale de » – « France »). En ancrant les LLMs sur ces bases factuelles vérifiables, plusieurs études montrent des réductions drastiques des hallucinations. Le framework KGT (Knowledge Graph-based Thought), publié en janvier 2025, surpasse les méthodes existantes de 33% en oncologie en faisant raisonner l’IA sur le schéma du graphe avant de générer une réponse.
Troisième piste fascinante : l’IA neurosymbolique, qui combine les réseaux neuronaux avec des règles logiques formelles (« si A alors B », règles mathématiques, contraintes sémantiques). Pensez-y comme à un copilote rationnel qui vérifie en permanence que l’IA respecte les lois de la logique. DeepSeek de Chine utilise déjà des techniques apparentées via le « distillation learning ».
Implications concrètes pour le marketing digital
Pour nous, marketeurs, ces avancées redessinent radicalement la gouvernance des contenus IA. Premier enseignement : ne jamais faire confiance aveuglément aux citations, statistiques ou références générées par un LLM.
Workflows recommandés basés sur la recherche :
- Génération multi-modèles + consensus : Interrogez GPT-4, Claude et Gemini sur la même question factuelle. Si les réponses divergent significativement, red flag absolu.
- RAG systématique pour les faits : Ne laissez jamais l’IA générer des données factuelles « de mémoire ». Intégrez toujours une couche de récupération documentaire (vos propres bases de données, APIs tierces vérifiées).
- Validation humaine à points critiques : Identifiez les 3-5 assertions factuelles clés dans chaque contenu et vérifiez-les manuellement. Les outils d’entropie sémantique peuvent automatiser la détection des zones à risque.
- Prompting défensif : Utilisez des prompts du type « Réponds UNIQUEMENT si tu es certain à plus de 90%. Sinon, dis ‘Information insuffisante’ et suggère des sources à consulter. »
Cas d’usage à risque maximal : benchmarks concurrentiels (chiffres de marché), études de cas clients (dates, métriques, citations), contenus réglementés (allégations santé, conformité RGPD), briefs techniques (specs produits, intégrations). Dans ces contextes, l’investissement dans des solutions avancées (KG personnalisés, pipelines RAG robustes) devient non négociable.
L’opportunité stratégique ? Les marques qui développent des workflows IA-humain robustes gagnent un avantage concurrentiel durable. Pendant que vos concurrents publient du contenu truffé d’hallucinations subtiles (et donc pénalisé par les algorithmes de qualité), vous construisez une réputation de fiabilité factuelle – un signal de plus en plus valorisé par les moteurs de recherche dans l’ère post-SGE (Search Generative Experience).
Ce qu’il faut retenir : l’ère de l’IA vérifiable
Les hallucinations ne disparaîtront pas – c’est désormais mathématiquement établi. Mais contrairement au discours fataliste, la recherche montre qu’elles sont détectables, quantifiables et mitigeables avec les bonnes approches. Le futur ne sera pas « IA sans hallucinations » mais « IA avec conscience de ses propres limites » – un changement de paradigme fondamental.
Pour les professionnels du marketing digital, cela signifie développer une littératie des hallucinations : savoir où, quand et comment l’IA est susceptible de vous induire en erreur. Les outils arrivent (plusieurs startups développent des solutions d’entropie sémantique en SaaS), mais la compétence humaine reste irremplaçable pour l’instant.
La question n’est plus « L’IA va-t-elle remplacer les rédacteurs ? » mais « Qui saura orchestrer intelligemment la collaboration humain-IA pour produire du contenu à la fois scalable ET véridique ? » La réponse à cette question déterminera les leaders du marketing digital dans les trois prochaines années.
Pour aller plus loin : bibliographie sélective
Articles académiques clés :
- Detecting hallucinations in large language models using semantic entropy – Nature, juin 2024. L’article fondateur sur l’entropie sémantique, peer-reviewed.
- Why Language Models Hallucinate – OpenAI, septembre 2025. Le papier qui a lancé le débat, avec démonstrations mathématiques complètes.
- Knowledge Graphs, Large Language Models, and Hallucinations: An NLP Perspective – Web Semantics, décembre 2024. Revue systématique sur l’intégration KG-LLM.
Outils et frameworks open-source :
- Awesome Hallucination Detection – Repository GitHub maintenu par l’Université d’Édimbourg, recensant papiers et implémentations.
- Semantic Entropy Probes (SEPs) – ArXiv, juin 2024. Version optimisée pour la production de l’entropie sémantique.
Analyses de l’industrie :
- OpenAI admits AI hallucinations are mathematically inevitable – Computerworld, analyse détaillée des implications business.
- Hallucination Mitigation for RAG: A Review – Mathematics (MDPI), mars 2025. État de l’art sur les techniques RAG anti-hallucination.
- Knowledge graph–based thought for pan-cancer question answering – GigaScience, janvier 2025. Cas d’application concret du KGT avec résultats mesurables.
Ce contenu vous a plu ?
Inscrivez-vous gratuitement à notre newsletter et recevez chaque semaine l’actualité du SEO directement dans votre boîte email. Vous pouvez vous désabonner à tout moment !