

L’ère de la recherche par mots-clés touche à sa fin. Après vingt-cinq ans de domination, le paradigme qui a fait la fortune de Google montre ses limites face aux nouvelles attentes créées par ChatGPT, Claude et autres assistants conversationnels. Cloudflare et Microsoft viennent de dévoiler leur réponse à cette mutation : NLWeb et AutoRAG, une infrastructure qui transforme n’importe quel site web en interface conversationnelle accessible aux humains comme aux agents IA. Une révolution qui pourrait redistribuer les cartes de l’économie du contenu en ligne.
Le constat : un web inadapté à l’ère de l’IA
Le diagnostic est sans appel. Les utilisateurs ne veulent plus « chercher » : ils veulent obtenir des réponses. La recherche par mots-clés, qui obligeait les visiteurs à taper des termes précis, cliquer sur des liens, parcourir des pages et reconstituer eux-mêmes l’information, appartient déjà au passé. Nous sommes passés des moteurs de recherche aux moteurs de réponses.
Mais le problème ne concerne pas uniquement les humains. Les sites web font face à une nouvelle catégorie de visiteurs : les agents IA. Ces programmes autonomes capables d’accomplir des tâches complexes butent sur les mêmes obstacles que les utilisateurs humains. Pire encore, ils doivent scraper les pages web comme ils peuvent, sans protocole standardisé, sans moyen fiable d’accéder au contenu structuré. Pour les éditeurs, c’est une double peine : leurs sites restent difficiles d’accès pour les utilisateurs tout en étant vulnérables aux aspirations sauvages de contenus par des agents incontrôlés.
L’ancien modèle reposait sur une hypothèse simple : les utilisateurs tapent des mots-clés, le site retourne une liste de liens classés par pertinence. Cette hypothèse ne tient plus. Les utilisateurs, habitués aux interfaces conversationnelles, attendent désormais des réponses directes, contextualisées, et formulées en langage naturel.
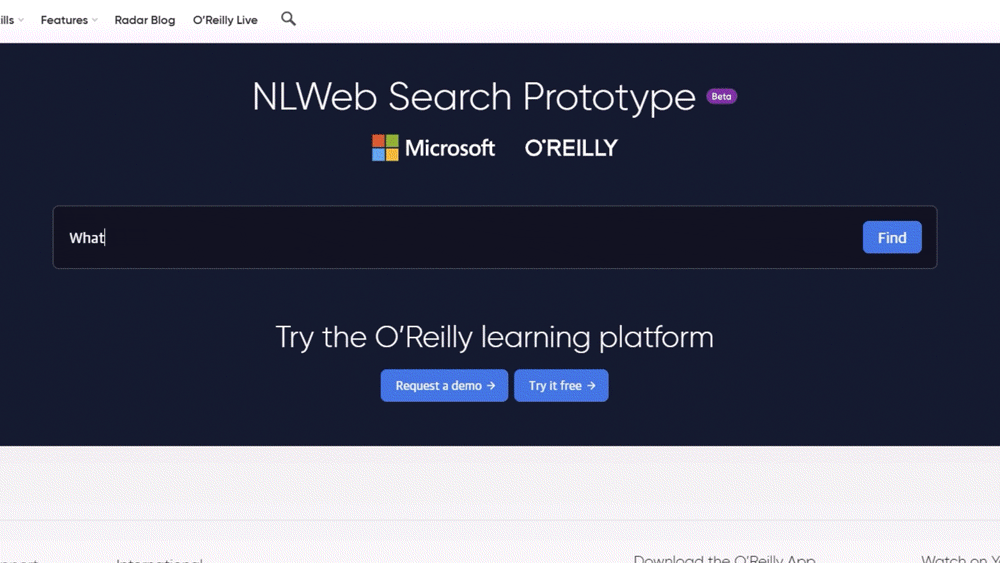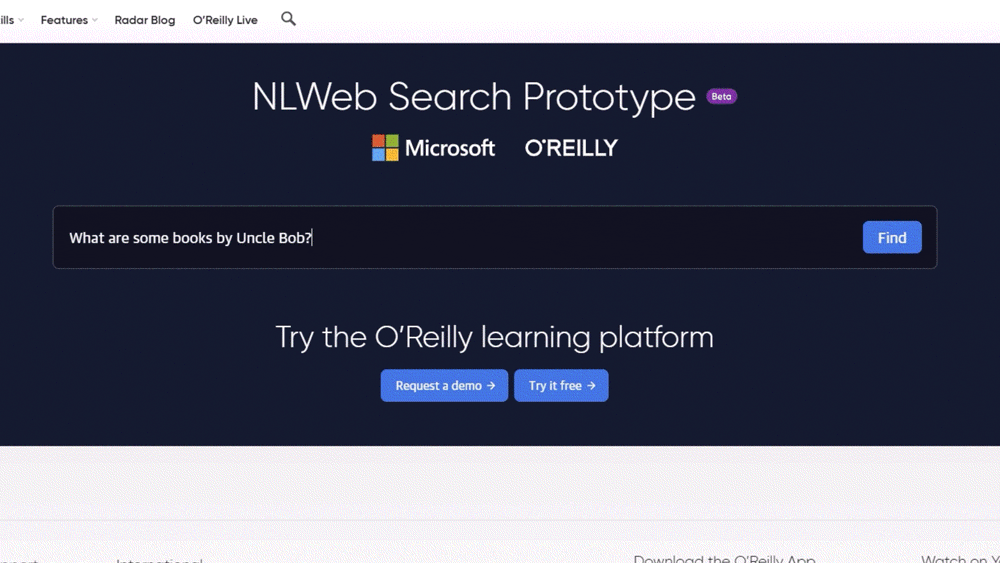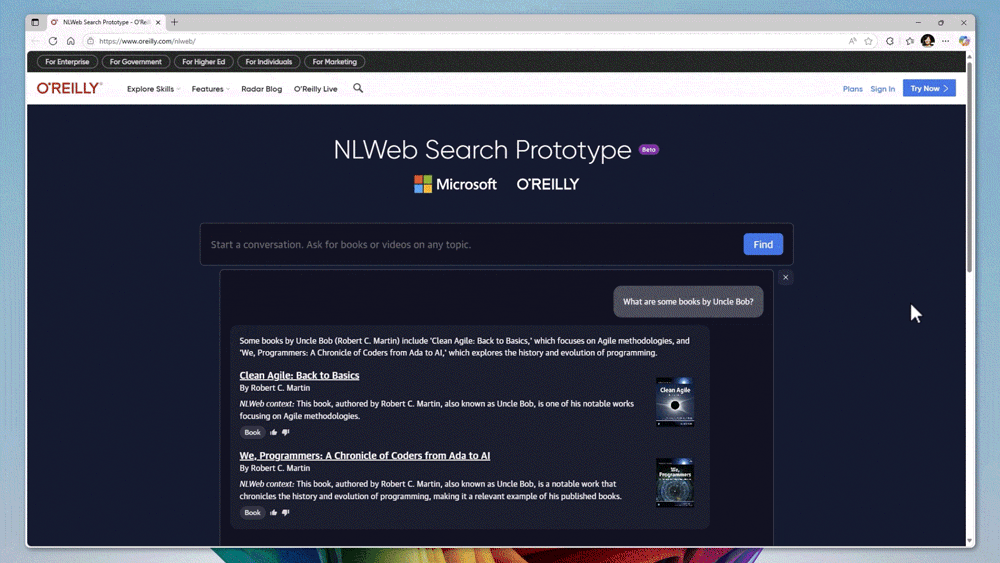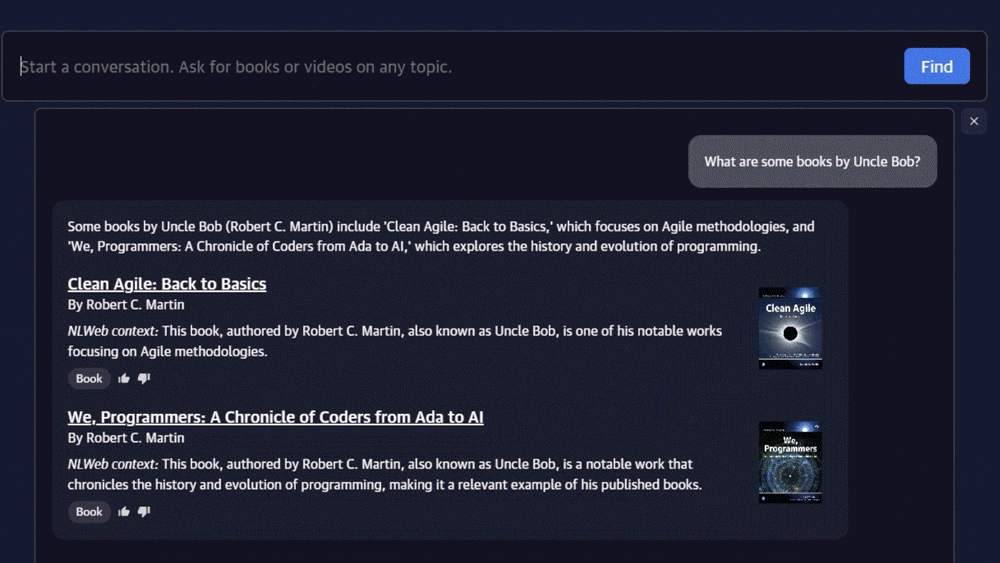
La réponse technique : quand les standards ouverts rencontrent l’infrastructure cloud
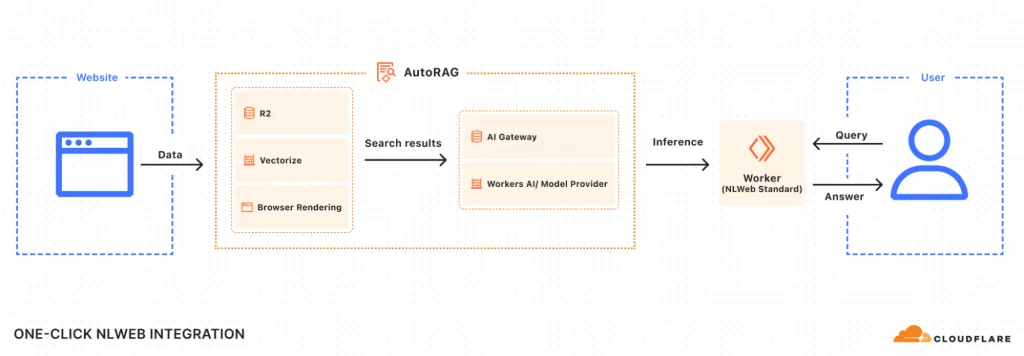
Face à ce constat, Cloudflare et Microsoft proposent une approche qui combine standardisation et simplicité de déploiement. Au cœur du dispositif : deux composants complémentaires.
NLWeb est un projet open source développé par Microsoft qui définit un protocole standard pour les requêtes en langage naturel sur les sites web. Chaque instance NLWeb fonctionne également comme un serveur MCP (Model Context Protocol), un standard émergent qui permet aux agents IA de dialoguer avec différentes sources de données de manière interopérable. Concrètement, NLWeb standardise la façon dont on peut « parler » à un site web, que l’on soit un humain ou une machine.
AutoRAG, l’infrastructure de Cloudflare, transforme cette vision en réalité opérationnelle. RAG signifie Retrieval-Augmented Generation (génération augmentée par récupération), une technique qui consiste à combiner une base de connaissances indexée avec un modèle de langage pour générer des réponses pertinentes. AutoRAG est une implémentation managée de cette approche, spécifiquement conçue pour les sites web.
Le pipeline technique est sophistiqué mais entièrement automatisé. Le système utilise Browser Rendering pour capturer le contenu JavaScript dynamique, une nécessité dans un web moderne où de nombreux sites génèrent leur contenu côté client. Les pages crawlées sont stockées dans R2, le service de stockage objet de Cloudflare, avant d’être transformées en embeddings – des représentations vectorielles du contenu qui permettent la recherche sémantique. Ces embeddings sont ensuite indexés dans Vectorize, une base de données vectorielle managée qui permet de retrouver des contenus similaires sans nécessiter de correspondance exacte de mots-clés.
La recherche sémantique constitue le cœur de l’innovation. Contrairement à la recherche par mots-clés qui cherche des correspondances textuelles exactes, elle comprend le sens des requêtes et peut retrouver des contenus pertinents même s’ils utilisent un vocabulaire différent. Une requête comme « comment réduire mes coûts cloud ? » peut ainsi retrouver des articles parlant d' »optimisation budgétaire » ou d' »économies d’infrastructure » sans que ces termes exacts n’apparaissent dans la question.
L’architecture sous le capot : résoudre les défis d’échelle
Pour gérer des sites pouvant contenir jusqu’à 100 000 pages, l’équipe Cloudflare a dû repenser son architecture. Le défi principal : traiter massivement du contenu sans dépasser les limites de mémoire des Workers, ces fonctions serverless qui constituent la couche d’exécution de Cloudflare.
La solution repose sur des Durable Objects, des objets persistants et distribués qui maintiennent un état à travers les requêtes. Deux types orchestrent le système. Le JobManager supervise l’ensemble d’une synchronisation : mise en file d’attente des pages, extraction et embedding du contenu, mise à jour de la base vectorielle. Un seul JobManager peut tourner par site à la fois, garantissant la cohérence des données.
Les FileManagers résolvent un problème plus subtil. Initialement, un seul Durable Object tentait de traiter plusieurs fichiers en parallèle, mais avec une limite de 128 Mo de RAM, il saturait rapidement. La nouvelle approche distribue le travail : chaque FileManager traite un seul fichier, et le système en lance jusqu’à vingt en parallèle. Cette architecture transforme une limite matérielle (128 Mo) en capacité distribuée (2,5 Go effectifs par batch).
Le crawling lui-même respecte les conventions du web. Le système lit les fichiers sitemap.xml et robots.txt pour identifier les pages autorisées, exactement comme le ferait un moteur de recherche classique. Mais contrairement à ces derniers, AutoRAG re-crawle et ré-indexe automatiquement, maintenant la base de connaissances à jour sans intervention manuelle.
Deux interfaces pour deux publics
Le Worker déployé expose deux points d’accès distincts, répondant à des besoins différents.
L’endpoint /ask implémente la spécification NLWeb pour les interactions conversationnelles. Il alimente l’interface utilisateur accessible à la racine du site et un widget embeddable via /snippet.html. Le système maintient un historique de conversation, permettant aux requêtes de s’appuyer sur les échanges précédents. Une fonctionnalité de décontextualisation automatique des requêtes améliore la qualité de récupération : si un utilisateur demande « Et pour les autres pays ? », le système reformule automatiquement la requête complète en fonction du contexte conversationnel.
L’endpoint /mcp cible les agents IA. En implémentant le Model Context Protocol, il offre un accès structuré et contrôlé au contenu du site. Les agents peuvent ainsi interroger le site de manière fiable, avec des réponses formatées de façon prévisible, plutôt que de devoir scraper des pages HTML et en extraire l’information. Pour les éditeurs, c’est un changement de paradigme : passer d’un accès ouvert mais chaotique à un accès contrôlé mais structuré.
L’enjeu économique : nouveaux modèles de monétisation
La simplicité de déploiement masque une transformation économique profonde. Joe Marchese, associé chez Human Ventures, ne s’y trompe pas : « Les défis des éditeurs sont bien connus, tout comme les risques que l’IA accélère l’effondrement de modèles économiques déjà fragilisés. Cependant, avec NLWeb et AutoRAG, il existe une opportunité de réinitialiser la nature des relations avec les audiences. Un engagement plus direct sur les environnements possédés et exploités par les éditeurs crée un nouveau potentiel de monétisation. »
La promesse est double. D’une part, retenir l’audience sur le site de l’éditeur plutôt que de l’envoyer vers Google ou d’autres agrégateurs. Les utilisateurs obtiennent leurs réponses directement, valorisant la marque et la voix éditoriale. D’autre part, contrôler l’accès des agents IA ouvre de nouvelles pistes : facturer l’accès API, établir des partenariats avec certains agents, ou conditionner l’accès à des accords de partage de revenus.
Mais cette vision se heurte à plusieurs réalités. Les métriques traditionnelles (pages vues, taux de clics, temps passé sur le site) perdent leur sens dans un modèle conversationnel. Comment monétiser une réponse directe plutôt qu’une page web ? La publicité display, colonne vertébrale du web gratuit, n’a plus d’emplacement évident dans une interface conversationnelle. Les éditeurs devront inventer de nouveaux indicateurs de performance et expérimenter des modèles économiques hybrides, entre abonnements, accès API freemium, et possibles formats publicitaires conversationnels.
Les zones d’ombre et limites structurelles
Aussi prometteuse soit-elle, l’approche NLWeb/AutoRAG n’échappe pas aux contraintes techniques et interrogations stratégiques.
Les limites d’échelle constituent le premier frein. Le plafond de 100 000 pages indexables exclut de facto les très grands sites médias ou les marketplaces avec des millions de références produits. Cette limite n’est pas arbitraire : elle reflète les contraintes économiques et techniques d’un service managé. Dépasser ce seuil nécessiterait une tarification et une architecture différentes.
La qualité du crawling soulève des questions plus subtiles. Même avec le rendu JavaScript, certains contenus échappent au crawler : les expériences fortement personnalisées, les contenus derrière des paywalls partiels, les interfaces avec états complexes. Un site de e-commerce dont les fiches produits se construisent dynamiquement selon le profil utilisateur ne sera jamais correctement indexé par un crawler générique.
Le contrôle d’accès reste flou. L’article mentionne les « agents de confiance » sans préciser les mécanismes d’authentification et d’autorisation. Comment un éditeur définit-il quels agents peuvent accéder à son contenu ? Peut-il différencier les accès selon l’agent (OpenAI vs Anthropic vs agents d’entreprise) ? Peut-il auditer qui accède à quoi ? Ces questions, essentielles pour les éditeurs soucieux de contrôler leur contenu, restent largement ouvertes.
La fidélité des réponses pose un défi inhérent aux systèmes RAG. Le contenu original, rédigé avec une intention éditoriale précise, est transformé en réponse générée par un modèle de langage. Cette transformation peut introduire des biais, des approximations, voire des erreurs. Un article nuancé peut être résumé de façon binaire. Un contenu ironique peut être pris au premier degré. Les éditeurs perdent le contrôle sur la formulation finale de leur message.
La dépendance à Cloudflare, bien que le protocole NLWeb soit ouvert, reste substantielle. L’infrastructure s’appuie sur R2, Vectorize, Workers AI et Browser Rendering – autant de services propriétaires. Migrer vers un autre fournisseur nécessiterait de reconstruire l’ensemble de la chaîne. Cette dépendance a un coût, tant financier (tarification au volume) que stratégique (dépendance à la feuille de route produit de Cloudflare).
Enfin, les questions juridiques autour des droits d’auteur demeurent non résolues. Quand un agent IA accède au contenu via l’API MCP et génère une réponse, qui est responsable de cette transformation ? L’éditeur qui expose l’API ? L’opérateur de l’agent qui consomme le contenu ? Le fournisseur du modèle de langage ? Les jurisprudences sont encore inexistantes, et les éditeurs s’exposent à des risques mal calibrés.
Vers un web conversationnel par défaut ?
NLWeb et AutoRAG incarnent une vision : celle d’un web où chaque site serait nativement conversationnel, où la distinction entre « page web » et « application IA » s’estomperait. R.V. Guha, créateur de NLWeb et Technical Fellow chez Microsoft, résume l’ambition : « Ensemble, NLWeb et AutoRAG permettent aux éditeurs d’aller au-delà des barres de recherche, en rendant les interfaces conversationnelles simples à créer et déployer. »
Cette vision s’inscrit dans un mouvement plus large : celui du web agentic, un web pensé pour les agents autonomes autant que pour les humains. Les signes s’accumulent. OpenAI, Anthropic et Google développent tous des agents capables d’interagir avec le web. Le Model Context Protocol, soutenu par Anthropic, gagne en adoption. Les navigateurs intègrent progressivement des capacités IA natives.
Mais la transition ne sera ni immédiate ni sans friction. Les éditeurs historiques, déjà fragilisés par des années de pression sur leurs modèles économiques, abordent cette transformation avec prudence. Les grands agrégateurs – Google en tête – n’abandonneront pas sans combattre une position dominante construite sur vingt-cinq ans. Et les utilisateurs eux-mêmes devront apprendre de nouveaux comportements, passer de la navigation par liens à l’interrogation conversationnelle.
Le succès de NLWeb et AutoRAG dépendra autant de l’adoption par les éditeurs que de l’émergence d’un écosystème d’agents IA respectueux du protocole. Un standard n’a de valeur que s’il devient effectivement standard. Microsoft et Cloudflare parient sur une adoption rapide, rendue possible par la simplicité de déploiement. Le pari est risqué mais cohérent : dans un monde où l’IA redéfinit les usages, les infrastructures qui simplifient l’adaptation ont un avantage décisif.
Ce qui se joue dépasse la simple évolution technique. C’est la répartition de la valeur dans l’économie du contenu qui est en jeu. Soit les éditeurs reprennent le contrôle de la relation avec leur audience via des interfaces conversationnelles natives, soit ils deviennent de simples fournisseurs de données brutes pour des agents IA contrôlés par d’autres. NLWeb et AutoRAG proposent une troisième voie : celle d’une infrastructure standardisée mais décentralisée, où chaque éditeur garde la maîtrise de son contenu tout en participant à un écosystème interopérable.
Les prochains mois seront décisifs. Si suffisamment d’éditeurs adoptent NLWeb, si suffisamment d’agents le supportent, le protocole pourrait effectivement devenir un standard de facto. Dans le cas contraire, il rejoindra la longue liste des initiatives prometteuses mais prématurées, victimes d’un problème classique de coordination : tout le monde y gagne si tout le monde adopte, mais personne ne veut être le premier.
Pour aller plus loin
Sur les standards et protocoles
- Model Context Protocol – Documentation officielle Anthropic
- Introducing NLWeb – Article Microsoft
- GitHub du projet NLWeb
Sur les architectures RAG et recherche vectorielle
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks – Le papier fondateur sur RAG (Lewis et al., 2020)
- Documentation AutoRAG de Cloudflare
Sur l’évolution du web et l’IA
- The Future of Search in an AI-First World – Analyse de Benedict Evans
- AI and the Automation of Work – O’Reilly Media
Sur les enjeux économiques pour les éditeurs
- The Economics of AI-Generated Content – Ben Thompson / Stratechery
- Publishers and AI: Threat or Opportunity? – Nieman Lab
Ce contenu vous a plu ?
Inscrivez-vous gratuitement à notre newsletter et recevez chaque semaine l’actualité du SEO directement dans votre boîte email. Vous pouvez vous désabonner à tout moment !